



Dobili ste dokumente: Šta sad?

Dobili ste dokumente: Šta sad?
Ovaj tekst je originalno objavljen pod naslovom You Got the Documents. Now What?. Tekst prenosimo uz dozvolu autora Jonathana Straya.
Čestitam! Vaš zahtjev za slobodnim pristupom informacijama je konačno dao rezultat u obliku velike smeđe koverte u poštanskom sandučiću. Sretni ste dobitnik tek otkrivene sočne informacije. Uspjeli ste da skinete sve PDF-ove sa vladinog portala iz kamenog doba. Sve što je preostalo jeste da to sada istražite.
Bilo bi dobro kada bi to bilo tako jednostavno.
Vaši sljedeći koraci zavise od toga šta imate i šta pokušavate da uradite. Možda imate jednu stranicu, a možda milion. Možda počinjete sa visokom hrpom papira ili sa CSV fajlom ili sa bilo čime između to dvoje. Možda već znate šta tačno tražite, a možda je ona anonimna dojava bila izluđujuće neodređena. Tokom svog rada u Overview, softveru za pretraživanje dokumenata, nailazio sam na gotovo sve probleme koje jedan novinar može imati sa pričom zasnovanom na dokumentima. Bilo je tu nečitljivih formata, hrpa papira i čitanja do kasno u noć. Ovaj prilog je organizovan u obliku blok dijagrama, tj. niza pitanja koje možete postaviti sami sebi – ili ih upotrijebiti da pomognete svojim kolegama koji tek počinju da rade sa podacima – da biste znali šta da uradite kada dokumenti konačno stignu.
Da li su dokumenti na papiru?
U ljeto 2012. godine, AP-ov data novinar Jack Gillum je želio da sazna da li kandidat za američkog potpredsjednika Paul Ryan privatno prima isti onaj novac za poticaje od vlade koji javno kritikuje kao rasipnički. Članovi Kongresa nisu dužni da se povinuju zahtjevima za slobodnim pristupom informacijama, ali federalne agencije jesu. Gillum je zahtjev za Ryanovom korespondencijom poslao na adrese više od 300 agencija i ono što je dobio nazad su papiri. U blogu o tom procesu, Mike Oreskes iz AP-a objašnjava: "Tokom sljedećih sedam sedmica, hrpa stranica koje je vlada slala Gillumu je stalno rasla u jednom uglu njegovog radnog stola – na 30 cm, zatim na 60 cm i više. On je za svaki fajl stranice elektronski skenirao i postavljao ih na AP-ov interni „APDocs“ DocumentCloud server."
Ovo ilustruje prvi princip rada sa dokumentima na papiru: skinite ih sa papira. Ako planirate da tražite, analizirate, sarađujete, objavljujete ili zapravo bilo šta sa svojim dokumentima osim da ih čitate sami u svojoj sobi, prvi korak je da ih skenirate. Idealno bi bilo pohraniti ih u odgovarajući centralni server – preporučujem DocumentCloud kao rješenje opšte namjene, o čemu ćemo više govorite dalje u tekstu.
Možda će vas iznenaditi količina papira s kojom se još uvijek radi u u data novinarstvu. Prema anketi učesnika našeg webinara o pretraživanju dokumenata, u polovini slučajeva novinari počinju istraživanje sa dokumentima na papiru (za razliku od digitalnih fajlova s dokumentima). Veliki dio tih dokumenata potiče od vlasti, koje obično putem papira odgovaraju na zahtjeve za slobodnim pristupom informacijama. Tu se ne radi samo o zastarjelim sistemima: papir je jedini format koji apsolutno svako razumije, dok se mnogi ljudi još uvijek ne osjećaju lagodno sa digitalnim alatima za uređivanje.
Slabiji skeneri se sada mogu nabaviti za manje od 100 američkih dolara, ali ako imate veliku količinu papira, biće vam potrebno nešto što ima ulagač papira. Većina fotokopir/faks aparata su istovremeno i skeneri, tako da u svom uredu možda već imate profesionalnu opremu. Ili lokalna fotokopirnica može za vas obaviti skeniranje. Rezultat skeniranje će biti jedan ili više dokument fajlova, obično u PDF formatu.
Gillum je skenirao dokumente kako su pristizali, koristeći fotokopir aparat u svom uredu. Na kraju je imao gotovo 9000 stranica, koje je analizirao u jednoj od ranijih verzija softvera Overview, te je došao do odgovora koji je tražio:
"Republikanski potpredsjednički kandidat Paul Ryan je fiskalni konzervativac, zagovarač smanjivanja uticaja vlasti i kritičar federalnih davanja. Ali, prema analizi 8.900 stranica korespondencije između Ryanovog ureda i više od 70 izvršnih agencija koju je izvršio Associated Press, Ryan je kao kongresmen u Wisconsinu lobirao za desetine miliona dolara u ime svog biračkog tijela za one vrste davanja protiv kojih sada vodi kampanju."
— Ryan tražio federalnu pomoć iako je zagovarao rezanje troškova (Ryan Asked for Federal Help as he Championed Cuts), Jack Gillum, AP, 12.10.2012.
Imate li tekstualne fajlove ili fajlove sa slikama?
Skeniranje listova papira, što se tiče kompjutera, zapravo ne proizvodi „tekst“, već slike. Vama ili meni su svi PDF fajlovi isti: možete otvoriti fajl i pregledati stranice. Ali, fajlovi napravljeni skeniranjem listova papira su zapravo slike teksta.
Digitalna slika se pohranjuje kao jačina osvjetljenja svakog piksela, dok se digitalni tekst predstavlja upotrebom standardizovanih kodova za svako slovo, broj i simbol koji se koriste na svakom jeziku na svijetu. Ako želite da pretražujete, analizirate ili čak da režete i lijepite iz svojih dokumenata, oni treba da budu u tekstualnom formatu. Većina novinara će u nekom trenutku naići na ovaj problem, jer čak i kada dokumenti stignu u elektronskom obliku, to mogu zapravo biti slike.
Pojedini formati fajlova pohranjuju jedino tekst, kao što su Word dokumenti ili TXT, RFT ili HTML fajlovi. Pojedini formati fajlova pohranjuju jedino slike, kao što su JPEG, TIFF, GIF ili PNG. PDF fajl može sadržavati ili slike teksta (pohranjene kao piksele) ili tekstualne podatke (pohranjene kao znakovne kodove). Da biste utvrdili da li vaš PDF fajl sadrži slike ili tekst, otvorite ga u svom omiljenom pregledniku i pokušajte da tražite, označavate, siječete i lijepite sadržaj. Ako je bilo šta od toga moguće, fajl sadrži tekst (a može sadržavati i prvobitne slike stranica i ponovo sačinjen tekst u skrivenom sloju).
- Za manje fajlove možete pokušati s besplatnim konverterima, kao što je onlineocr.net.
- Mnogi online konverteri za određeni iznos podržavaju i veće fajlove.
- Najveća tačnost se generalno postiže s komercijalnim OCR softverom, kao što su Abbyy ili OmniPage. Acrobat Pro takođe može vršiti OCR.
- Open source paket Tesseract takođe dobro funkcioniše u mnogim slučajevima, a možete ga ugraditi u korisničke skripte ili aplikacije za obradu.
- Vaša lokalna fotokopirnica će takođe rado obaviti optičko znakovno prepoznavanje. Čak ga mogu vršiti tokom skeniranja ako za početak imate listove papira.
- DocumentCloud i Overview će takođe uraditi optičko znakovno prepoznavanja kao dio procesa unosa.
Radi li se tu zaista o brojevima?
Sada imate dokumente u digitalnom obliku, koji sadrži digitalni tekst. Nekad ćete htjeti da taj tekst pročitate, pretražite ili kopirate. U drugim slučajevima vam zapravo trebaju brojevi.
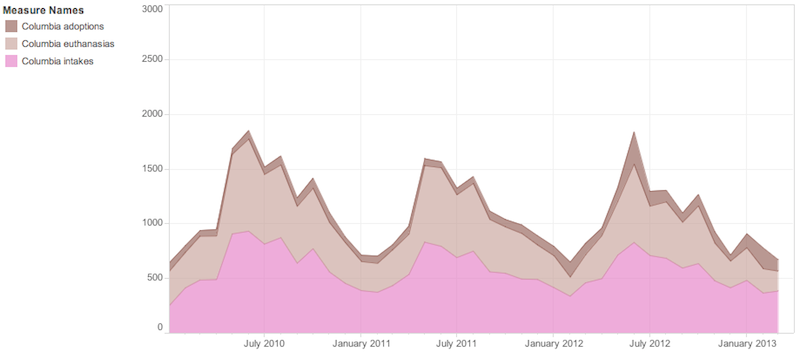
Prošlog ljeta je na Floridi donesen zakon kojim se zahtijeva od svih okružnih azila za životinje da učine dostupnim statističke podatke o broju primljenih, usvojenih i eutaniziranih životinja. Dvije sedmice kasnije, reporter WUFT-a Ethan Magoc je zatražio te podatke. Samo sedam od dvanaest okruga je bilo u stanju da pruži podatke, što pokazuje da zakon nije imao efekta. Ali, čak i ti okruzi koji su predočili podatke su samo dali PDF fajlove, a to je format koji ne može učitati nijedan softver za vizuelno prikazivanje podataka. U PDF fajlu se brojevi nalaze u tabelama koje kompjuter teško čita, što predstavlja još jednu prepreku.
Magoc je upotrijebio CometDocs da izvadi tabele u proračunske tablice u Excelu i da napravi vizuelni prikaz koristeći Tableau. Ovo je veoma čest problem. Vi tražite podatke i dobijete dokumente.
Priča Joela Hoffmana o telefonskoj liniji za podnošenje etičkih žalbi u San Diegu je još jedan primjer vađenja podataka koje zahtijeva dodatne korake. Hoffman je u ovom slučaju pokušao da vizuelno prikaže teme poziva upućenih na telefonsku liniju školskog odbora u San Diegu, ali je dokumente prvo trebalo optički prepoznati kao znakove, a zatim pretvoriti u proračunsku tablicu. Na kraju se pokaže da je vađenja podataka potrebno kako za jednostavne stvari kao što je objavljivanje budžetskih informacija, tako i za komplikovane stvari kao što je analiza troškova poslanika u parlamentu.
Kada su važni podaci blokirani unutar brojčanih tabela u vašim dokumentima, treba da ih izvadite u format proračunske tablice kao što je Excel ili u podatkovni format kao što je CSV prije nego što ih možete analizirati ili vizuelno predstaviti. Ovu konverziju ćete sasvim sigurno trebati napraviti ako ste na početku dobili dokumente na papiru, ali čak i digitalni fajlovi mogu biti u neupotrebljivim formatima kao što je PDF.
- Prvo pokušajte da obilježite tabelu u dokumentu i da je kopirate, a zatim je zalijepite u proračunske tablice u Excelu ili Googleu (pokušajte oboje, jer može dati drugačije rezultate).
- Tabula je open source aplikacija koju možete preuzeti i koristiti, a napravili su je data novinari upravo za vađenje tabela iz PDF fajlova.
- Postoji veći broj besplatnih online servisa koji mogu biti korisni, kao što su PDF to Excel, cometdocs i Zamzar.
- Ako ništa od toga ne uspije, možete pokušati sa komercijalnim alatima kao što su AbleToExtract (99 dolara) ili Monarch Professional (2.068 dolara).
Ako su vaši dokumenti HTML fajlovi, bilo da su pohranjeni na vašem kompjuteru ili su dostupni online, onda se koriste drugačije tehnike. Često uspijeva rezanje i lijepljenje, a postoje i dodaci za preglednike, kao što je Scraper, koji vam omogućavaju da označite tabelu na stranici i da iz nje preuzmete podatke. Alati kao što je Outwit Hub mogu obavljati složenije zadatke HTML procesuiranja, uključujući automatizirano preuzimanje podataka sa više stranica.
U najgorem slučaju, prebacivanje podataka u upotrebljiv format može biti odiseja samo za sebe, kao što je bilo u slučaju ažuriranja priče Dollars for Docs redakcije ProPublica.
Očekujte dosta posla ako imate mnogo dokumenata ili mnogo različitih formata tabela. Vaši dokumenti mogu sadržavati i struktuirane podatke koji nisu u tabelarnom obliku. Timothy Barmann iz lista Providence Journal je napravio novinarsku aplikaciju koja prati prisustvovanje državnih zakonodavaca sjednicama tako što je iz novina Predstavničkog doma i Senata vadio rubriku sa spiskom prisutnih, što je detaljno opisao.
Vađenje ove vrste podataka često zahtijeva neku vrstu korisničkog koda, ali ne uvijek – vidjeti ispod u dijelu o pričama koje govore o trendovima. Vađenje podataka iz dokumenata koji su i sami na početku predstavljali podatke je nešto što niko ne bi trebao da radi – izvori bi trebali da objavljuju podatke u formatima koji se lako koriste, u skladu sa najboljim praksama za otvorene podatke. Ali svijet nije savršen, a novinari će uvijek raditi na granici mogućeg, tako da postoje redovni događaji, tzv. PDF Liberation hackatons, na kojima se razvijaju bolji alati.
Najpodliji PDF za koji ja znam je godišnji podnesak predsjedničkog budžeta od strane Ministarstva odbrane, dužine 700 stranica gustog proreda sa stavkama u desetak različitih tabelarnih formata. To bi zapravo trebala biti baza podataka, a ne dokument, i ne vjerujem da je još iko uspio da iz njega izvuče cjelokupan skup podataka. Ipak, relativno je lako izvući konkretnu tabelu koristeći gore navedene alate.
Koliko dokumenata imate?
Prvi novinar koji je pokušao da piše o Wikileaks telegramima je bio David Leigh iz lista The Guardian. Materijal je stigao kao jedan jedini CSV fajl veličine 1,7GB koji je sadržavao 251.287 američkih diplomatskih telegrama od 1966. do 2010. godine. Ako ste ikada pokušali da otvorite fajl od 1,7GB, znate da to vjerovatno ne možete uraditi. Microsoft Word i Excel će jednostavno odbiti. Windows Notepad i Mac TextEdit će pokušati, ali će usporiti do puzanja. Leigh ove probleme prepričava u svojoj knjizi:
"Očigledno je da nema načina da on, kao ni bilo koji čovjek, može pročitati četvrt miliona telegrama. Odsječen od Guardianove mreže, nije mogao da pretvori ovaj materijal u pretraživu bazu podataka. A nije mogao ni učitati tako masivan fajl na svoj laptop i pretraživati ga običnim, jednostavnim novinarskim putem, kao dokument u programu za obradu riječi ili nešto slično. Jednostavno je bio preveliki.
Guardianov tehnički stručnjak Harold Frayman mu je pritekao u pomoć. Prije nego što je Leigh napustio grad, on je ovaj materijal podijelio u 87 dijelova, od kojih je svaki bio dovoljno mali da se može odvojeno pregledati. Onda je Leighu objasnio kako može upotrijebiti jednostavan program pod nazivom TextWrangler da u svim zasebnim fajlovima istovremeno traži ključne riječi ili fraze, te da rezultate predstavi u formatu koji je jednostavan za upotrebu."
—WikiLeaks: Unutar rata Juliana Assangea protiv tajnosti (Inside Julian Assange’s War on Secrecy), David Leigh, Guardian Books, 2011.
Na sreću, u novinarskom poslu se obično ne barata sa 250.000 dokumenata. Prosječna veličina skupa dokumenata u novinarstvu je oko 10.000 stranica, što je dovoljno malo da ne sruši većinu softvera, a ipak možete sve iscrpno pročitati ako imate strpljenja. A novinari ga često imaju. Bio sam u AP-u kada je objavljeno 24.199 stranica e-mailova Sarah Palin – naravno na papiru – i mi smo na toj vrućoj priči radili tako što je desetak novinara bilo zaduženo da pročita e-mailove u neprekidnim smjenama tokom jednog vikenda.
Ali i 10.000 stranica je ipak puno, a skupovi dokumenata su nekada mnogo veći od toga. Evo nekoliko savjeta ako imate posla sa ogromnim količinama materijala:
- Ključno je da, ako je ikako moguće, izbjegnete da ručno radite na svakom dokumentu. Kada god se nađete u situaciji da radite nešto što se stalno ponavlja, pokušajte da smislite način da automatizujete taj zadatak ili da ga radite u velikim serijama.
- Rad sa mnogo podataka znači velike fajlove ili mnogo malih fajlova ili oboje. Svaki softver usporava kako se fajlovi povećavaju, a neki softveri imaju ograničenja veličine, kao što je maksimalan broj redova u proračunskoj tablici u Excelu, tako da vam može pomoći da materijal koji imate podijelite na više fajlova ili da izvučete samo one dijelove koji vas zanimaju. I obrnuto, pojedini zadaci su lakši ako možete spojiti mnogo fajlova u jedan.
- Steknite naviku da koristite naredbeni red, tj. command line. Alati koji se koriste preko naredbenog reda s lakoćom rade sa ogromnim skupovima podataka, mogu se koristiti za dijeljenje podataka na razne načine (vidjeti CSVKit, naprimjer) i napravljeni su da se kombinuju u složenije operacije. Ako ste novi u ovom svijetu, pokušajte sa The Command Line Murders.
- Apsolutno morate znati dvije naredbe: 'head' pokazuje prvih nekoliko redova fajla koliko god on bio dug, dok 'grep' pretražuje po fajlovima. Obje naredbe su već instalirane na Mac-u i Linux-u. Za Windows trebate instalirati naredbeni red koji je kompatibilan sa Unix sistemima, kao što su Cygwin ili Git Bash.
- Overview je napravljen upravo za dokumente velikog obima. Ovaj javni server trenutno podržava do 200.000 dokumenata po projektu.
Ovim su obuhvaćeni tehnički elementi, ali s povećanjem obima materijala, vaša strategija rada mora biti još sofisticiranija, naročito kada nije moguće iscrpno čitanje svake stranice – ili kada imate rok za udarnu priču. Sljedeća pitanja se tiču dva komplementarna pristupa sistematskom izvještavanju o velikom skupu dokumenata.
Tražite li pištolj iz kojeg se dimi?
Negdje sam već pisao o različitim vrstama priča zasnovanim na dokumentima, od kojih svaka zahtijeva drugačiji pristup. Ponekad će suštinu vaše priče činiti samo jedan ili nekoliko ključnih dokumenata – dokaz o nedjelu, važan izvještaj, presudan redak u svjedočenju. Ja to zovem „pištoljem iz kojeg se dimi“, a vaš je zadatak da ga pronađete.
Priča Jarrela Wadea za list Tulsa World je započela anonimnom dojavom: Uprava policije u gradu Tulsi je trošila milione dolara na kompjutere za policijska vozila koji nisu ispravno radili. On je znao da je u toku interna istraga, ali nije znao mnogo više od toga sve dok nakon podnošenja zahtjeva za pristup informacijama nije dobio gotovo 7000 stranica e-mailova. Na kraju je pronašao niz ključnih e-mailova gdje se dokumentuje ova loša odluka i njene okolnosti, kao što je sljedeći e-mail koji je direktor projekta vodnik Willa Dalsing uputio prodajnom zastupniku Panasonic-a:

Pretraživanje je neophodan alat za priče u kojima se krije pištolj iz kojeg se dimi. Morate biti u stanju da jednim upitom pretražite cijeli skup dokumenata, umjesto da ih pretražujete jedan po jedan. Viđao sam kako redakcije prave čitave Rails aplikacije samo da bi neki skup dokumenata postavili online, ali u današnje vrijeme nema potrebe za tim.
- Prvo pokušajte sa opcijom za pretraživanje u vašem operativnom sistemu. Vjerovatno biste ionako trebali svoj materijal postaviti na DocumentCloud, pa možete i tamo izvršiti pretraživanje.
- Za veći broj dokumenata (hiljade i više) ili za napredne pretraživačke opcije, koristite Overview. Ako vaši dokumenti predstavljaju struktuirane arhive, umjesto toga razmislite o Pandi.
- Ako imate neku vrstu običnih tekstualnih fajlova, možete vršiti pretraživanje više fajlova u programima kako što je SublimeText ili čak samo uz pomoć alata 'grep' u naredbenom redu.
- Ako je na vašim dokumentima izvršeno optično znakovno prepoznavanje (OCR – vidjeti iznad), oni mogu sadržavati OCR greške. Možete pokušati da koristite različite riječi za pretraživanje ili da upotrijebite višeznačno pretraživanje ako je dostupno.
- Dobro se upoznajte sa naprednim opcijama pretraživanja softvera koji koristite. To mogu biti boolean operatori, vremenski rasponi, citirane fraze, obični izrazi, mogućnost pretraživanja različitih područja u dokumentima (npr. naslovi nasuprot tijelu dokumenta) i tako dalje.
Ako ništa ne nađete, kako možete sigurno znati da niste nešto propustili? Važno je pokušati s različitim tehnikama pretraživanja i pažljivo dokumentovati na koji ste način tražili. Preporučujem da vodite dnevnik o upitima za pretraživanje koje ste pokušali i rezultatima svakog od njih. Takođe pokušajte da priču istražite na neki drugi način! Upotrijebite drugi alat, pronađite drugi skup dokumenata ili podataka na istu temu ili razgovarajte s upućenim izvorima.
Izvještavate li o trendu?
Druga vrsta priče zasnovane na dokumentima je priča o određenom trendu. Tada vas zanima generalni obrazac – o čemu e-mailovi najviše govore, da li se broj prijavljenih incidenata povećao ili smanjio, obrasci u prijavljenim slučajevima zlostavljanja. Ovo je drugačija vrsta izvještavanja koju neće riješiti pretraživač.
Krajem 2011. godine sam došao do 4.500 stranica dokumenata iz Iračkog rata – internih istraga State Departmenta o aktivnostima naoružanih pripadnika privatnih zaštitarskih firmi koje su radile za američku vladu – s kojih je nedavno skinuta oznaka tajnosti. Znao sam da je bilo nekoliko incidenata koji su izazvali veliku pažnju, kao što je ubistvo 17 iračkih civila u Bagdadu u oktobru 2007. godine. Ali, s ovom količinom materijala – u suštini zasebnim dosjeima o svim slučajevima u kojima je neki pripadnik zaštitarske firme pucao iz svog oružja – želio sam da odgovorim na teže pitanje: šta su ovi naoružani pripadnici zaštitarskih firmi radili kada nisu bili u vijestima? Da li su takve svireposti bile tipične ili rijetke?
Tražio sam opšte obrasce, ali nisam imao nikakvu ideju šta bi oni mogli biti. To je vrsta problema za čije je rješavanje napravljen Overview. Nakon skeniranja i obavljanja optičkog znakovnog prepoznavanja (OCR), učitao sam dokumente u Overview, koji ih je automatski sortirao prema temi i dao mi vizuelni prikaz sadržaja svakog direktorija. Pronašao sam neprijateljske raketne napade, zračne operacije i druge zanimljive stvari, ali uglavnom sam otkrio da su pripadnici zaštitarskih firmi rijetko pucali, a i kada jesu, obično su pucali u motore automobila.
Dokumenti pokazuju da su ovi pripadnici najviše pucali na civilna vozila koja su se približavala kako bi zaštitili povorke američkih vozila od opasnosti bombaša samoubica. Dokumenti takođe pokazuju koliko su često hici ispaljivani i pružaju uvid u pojačani nadzor State Departmenta nad privatnim zaštitarskim firmama koje su radile za njih za vrijeme rata.
Iz State Departmenta su nam rekli da je 2007. godine u Iraku bilo 5.648 zaštićenih povorki diplomatskih vozila. Naša analiza je otkrila da se pucnjava dogodila samo u oko 2 posto slučajeva povorki vozila u Iraku 2007. godine.
— Šta su privatne zaštitarske firme radile u Iraku? (What did private security contractors do in Iraq?), Jonathan Stray, AP, 21.02.2012.
Overview je dobar za priče o trendovima zato što vam daje vizuelni prikaz tema u skupu dokumenata. Ovaj javni servis je besplatan, a kod je open source.
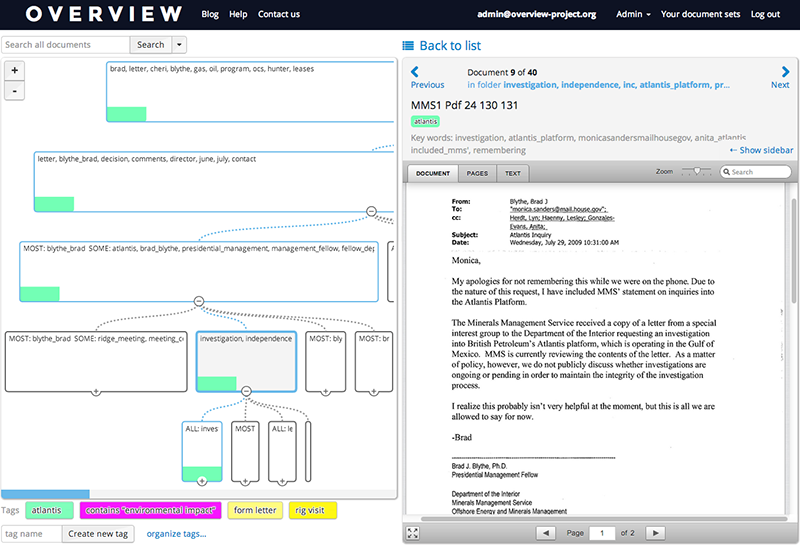
Overview može čitati gotovo bilo koji format dokumenta i sadrži naredbenu datoteku koja automatski, ako je to potrebno, vrši optičko znakovno prepoznavanje. Primjenjuje algoritme za prirodno procesuiranje jezika kako bi automatski sortirao dokumente u direktorije i poddirektorije na osnovu teme, a zatim pruža interaktivni vizuelni prikaz datoteka. Osnovna istraživačka strategija je da istražujete direktorije jedan po jedan, označavajući ono što nađete i ulazeći dublje u poddirektorije kada naiđete na nešto zanimljivo.
Tu tehniku je koristio Tyler Dukes sa TV stanice WRAL kada se našao pred 4.500 stranica e-mailova okružnih vlasti Sjeverne Karoline. Sedamdeset hiljada gladnih porodica je ostalo bez bonova za hranu zbog kašnjenja u novom sistemu naknada na nivou ove američke države, a Duke je želio da otkrije zašto se to dogodilo. U prilogu za Source, on objašnjava kako je upotrijebio Overview da bi napravio priču o tome – tokom jednog poslijepodneva.
Ovakva vrsta otvorenog istraživanja predstavlja najopštiji pristup. Postoje i specijalizovanije tehnike za određenu vrstu priče o trendu, koje ja nazivam „kategoriziraj i izbroji“. U ovom slučaju, cilj je kategorizirati svaki dokument prema nekoj postavci koja se odnosi na konkretnu priču: dokument sadrži izvještaj o zlostavljanju ili ga ne sadrži; u svakom e-mailu se govori o prihodima od autorskih prava, brizi za očuvanje okoline, zabavama na poslu ili ni o čemu od toga; prevozno sredstvo o kojem se radi je avion, voz ili automobil. Priča se istražuje tako što se prvo prave kategorije, a zatim se broji koliko u svakoj kategoriji ima dokumenata.
Za svoj opsežan izvještaj o podzemnom tržištu usvojene djece u Americi, Ryan NcNeill, Robin Respaut i Megan Twohey iz Reutersa su analizirali više od 5.000 poruka na jednoj grupi za diskusije na Yahoo tokom petogodišnjeg perioda. Napravili su infografiku u kojoj sumiraju svoja otkrića: tokom ovog vremena je reklamirano 261 dijete iz 34 različite američke države. Više od 70% ove djece je rođeno u inostranstvu, u najmanje 23 različite zemlje. Takođe su dokumentovali broj slučajeva u kojima se navodi da djeca imaju poremećaje u ponašanju ili su bila žrtve ranijeg fizičkog ili seksualnog zlostavljanja. U kombinaciji sa emotivnim prepričavanjem određenih slučajeva, ove brojke jasno govore o prirodi i razmjeri ovog problema.
{kind=link}
Za obilježavanje dokumenata možete koristiti opcije označavanja (tagging) koje nudi Overview. To je brže od ručnog iscrpljujućeg pregleda, zato što Overview zajedno sortira slične dokumente, tako da odjednom možete označiti cijele direktorije. Ili upotrijebite napredno pretraživanje Overview-a da izbrojite koliko dokumenata odgovara određenom upitu ili da ih označite da biste ih pažljivije pregledali. Kada završite, možete eksportovati dokumente, sa njihovim tagovima, da biste napravili vizuelne prikaze ili vršili daljnu analizu.
Možete isprobati i tehnike uzimanja statističkih uzoraka, isto kao što biste napravili istraživanje javnog mnijenja tako što biste nazvali 1.000 nasumično odabranih osoba. Umjesto tačnog broja dokumenata u svakoj kategoriji, ova tehnika vam daje procjenu, uz granicu dozvoljenih grešaka. Ja sam ovu tehniku koristio da izvršim nezavisnu procjenu broja povreda i smrti civila u dokumentima o privatnim sigurnosnim firmama koje rade za američku vladu u Iraku, kao provjeru da bih bio siguran da su moje istraživačke metode pouzdane.
Trebate li objaviti dokumente?
Već sam nekoliko puta pomenuo DocumentCloud, a pomenuću ga još par puta. Napravljen je upravo za novinare i podržava mnoge stvari koje ćete možda imati potrebu da uradite sa dokumentima: učitavanje, OCR, pretraživanje, saradnja i objavljivanje. Koriste ga gotovo svi koji se bave ovim poslom, a korisnički računi su besplatni za novinare (uključujući freelancere), pa zatražite ovdje da otvorite račun.

DocumentCloud je zapravo jedini način ako trebate da objavite neke ili sve dokumente kao dio priče. Javno objavljivanje pojedinačnih dokumenata ili čitavih projekata je jednostavno. Sve ostalo je privatno i možete ga gledati samo vi i saradnici koje odredite. Da biste objavili dokumente, samo postavite link na stranicu s dokumentom. Ili možete u svoju priču umetnuti preglednik dokumenata. Možete dodati i javne ili privatne bilješke i na siguran način ukloniti informacije koje ne trebaju biti objavljene.
Ponekad vas sigurnosni ili pravni obziri mogu spriječiti da dokumente pohranite u Cloud. (Privatni dokumenti su zaista privatni na DocumentCloud.org, ali uvijek postoji mogućnost hakiranja ili sudskih naredbi.) U tom slučaju možete koristiti vlastiti interni DocumentCloud server za svoju redakciju, jer je ovaj softver open source.
S objavljivanjem dokumenata su povezani etički i pravni obziri, s mogućim problemima kao i sa svim drugim što objavljujete. Važno je zapamtiti jedan tehnički detalj: fajlovi s dokumentima mogu sadržavati informacije koje ne možete vidjeti kada ih samo pogledate. To mogu biti meta podaci, kao što je ime autora ili GPS lokacija na kojoj je fotografija snimljena, tako da se morate pobrinuti da na pravilan način izvršite digitalno brisanje da se ti podaci ne bi mogli ponovo vratiti.
Pojednostavite
Siguran sam da ovo predstavlja puno novih informacija. Ali malo je istraživačkih projekata koji obuhvataju sve ove korake, a nijedan od njih ne zahtijeva sve ove alate. Za većinu priča je sljedeći opšti način rada sasvim dovoljan:
Ako je dokument na papiru, skenirajte ga.
Ako su u pitanju brojevi, izvadite ih.
Ako je u pitanju nešto veliko ili se radi o trendovima, stavite to u Overview.
Inače, samo učitajte sve na DocumentCloud i tu radite.
Možda ćete otkriti da će vam biti potrebne neke od specijalizovanih tehnika o kojima sam govorio u ovom prilogu, ali možda i neće. Imate dokumente, pa sada počnite! Sretno.
Ovaj tekst je objavljen u sklopu projekta 'Public Data Now' podržanog od strane Holandske ambasade u BiH. Tekstove vezane za pristup podacima i data novinarstvo možete čitati u našem serijalu ovdje.